
Keine Erkenntnis ohne Ähnlichkeit
Michael Seibel • Empirie und Induktionsproblem, Henne oder Ei? Hinterm Horizont der Miniaturisierung (Last Update: 01.07.2020)
Man weiß es nicht, aber man vermutet es stark: Für menschliches Denken, das zu Entscheidungen welcher Art auch immer kommen will, ist das Erkennen von Ähnlichkeiten der elementarste erste Schritt, mit dem alles anfängt. Wenn Menschen offensichtlich im Laufe der Evolutionsgeschichte für etwas großes Talent entwickelt haben, dann für die Entdeckung von Ähnlichkeiten. Auch Metaphern, entlang deren ganz generell Denken und Sprechen fortschreiten, gründen nicht zufällig in Bewegungen entlang des Ähnlichen.
Deep Learning stellt sich der Herausforderung, die Aufgaben zu lösen, die von Menschen leicht auszuführen, von ihnen jedoch nur schwer oder gar nicht formal zu beschreiben sind - Probleme, die wir intuitiv lösen wie das Erkennen gesprochener Wörter oder Gesichter in Bildern.
Elementare Ähnlichkeit
Wir müssen die Behauptung, dass
Ähnlichkeiten zu erkennen eine besonders einfache Leistung ist,
schon deshalb sofort wieder zurücknehmen. Wir wissen längst
viel zu viel allein schon über die Physiologie selbst der
elementarsten visuellen Wahrnehmung, als dass wir das Erkennen von
Ähnlichkeiten für physiologisch simpel oder
voraussetzungslos halten dürfen.1
Wenn die visuelle Wahrnehmung des Menschen optische Reize aufnimmt,
verarbeitet und mit der Erinnerung abgleicht, geht sie weit über
die reine Aufnahme von Informationen hinaus. Allein schon die
optischen Täuschungen und vor allem die ganz unterschiedlichen
Möglichkeiten pathologischer Schädigungen und Ausfälle
beim Erkennen von Ähnlichkeiten zeigen unübersehbar, wie
vielfältig und elementar zugleich die unbewussten Verarbeitungen
sind, denen sämtliche distalen Außenweltreize sofort ab
der Reizaufnahme unterzogen werden. So ist etwa bei Anopsien die
optische Empfindung selbst gestört, während bei optischen
Agnosien die Assoziation des Gesehenen mit Erinnerungen gestört
ist, wodurch das Gesehene schlichtweg bedeutungsleer bleibt und damit
das Erkennen verhindert ist. Beide Störungen lassen sich
Läsionen unterschiedlicher Gehirnareale zuordnen. Und
unbestreitbar ist auch, dass die Bedeutung aufgenommener Reize
physiologisch auch bereits unterhalb der Bewusstseinsschwelle
eindeutig vom Abgleich mit Erinnerungen abhängt. So erfolgt die
Augenbewegung, mit der ein gesehenes Objekt verfolgt wird, spontan
und wird nicht bewusst gesteuert. Dennoch erkennt eine
Gedächtnisleistung, welche Objekte sich mit dem Augen zu
verfolgen lohnen. Es gibt ein Apriori der Gedächtnisleistung
beim Erkennen. Inhalte, deren dabei gedacht wird, entstammen
keineswegs allein den Erinnerungen, die das Individuum während
seines eigenen Lebens festhält, sondern seiner
Evolutionsgeschichte. In welchem rasanten Tempo auch immer ein Baby
seine Welt kennenlernt, seine Lerngeschwindigkeit wäre viel zu
langsam, als dass es sich, wenn es einem bewegten Objekt mit seinem
Blick folgt oder wenn es das Gesicht seiner Mutter erkennt, auf
persönliche Erfahrungen und Erinnerungen verlassen müsste.
Es bedarf angeborener Kriterien, einer inkorporierten Semantik2.
In unserem Fall fragen wir danach, was z.B. die Faszination der
Gegenstände ausmacht, auf die sich die frühkindliche
Aufmerksamkeit richtet. Es kann sich nicht um eine Semantik handeln,
mit der das Kind durch Erlernen bekannt geworden ist, aber es wirkt
funktional wie eine Semantik und integriert sich lebensgeschichtlich
perfekt in die Semantik ganzer Gesellschaften. Wir haben uns, wie es
scheint, daran zu gewöhnen, dass eine Semantik, etwas ganz und
gar Sprachliches, ebenso angeboren sein kann wie ein Leberfleck, noch
bevor auch nur der Laut gesprochen wird. Wenn uns die Genetik heute
zusehen lässt, wie ein Code, in den wir zunehmend mehr
biotechnologisch einzugreifen lernen, die Natur des Lebendigen
aufbaut, so scheint hier gerade das umgekehrte Verhältnis zu
herrschen. Hier generiert nicht ein Code die Natur des Lebendigen,
sondern die Natur wirkt, einmal ins Leben getreten, unmittelbar
selbst wie eine Sprache, an die der Mensch, wenn er artikuliert zu
sprechen begonnen hat, ein Leben lang Anschluss zu halten sucht mit
dem ganzen Aufwand, den es ihn kosten wird, zu lernen und, wenn es
sich trifft, zu verstehen.
Das erinnert nicht von ungefähr
an die platonische Ideenlehre, die allerdings Anfang und Ende
kurzschließt und das, was der weise gewordene Alte kaum
ausdrücken kann, an den Uranfang rückprojiziert. Etwas
erkennen heißt demnach immer auch, sich an etwas erinnern, das
sich ontogenetisch nicht lernen lässt, sondern eben nur
phylogenetisch. Nur dass diese Semantik, die im Aufmerken und in der
Zuwendung dem Spracherwerb vorausgeht, nicht jene Idee des Guten
ist, als die sie kulturell immer wieder ausgearbeitet wird.
Wenn man den Bogen von der Wahrnehmung von Ähnlichkeiten zum Erkennen schlagen möchte, klaffen sowohl bei der Frage nach der naturalen Mitgift im Rhythmus von Hinwendung und Abwendung wie bei dem schier unüberbrückbaren Graben zwischen der kulturellen Breite des Erkenn- und Erfahrbaren und der elementarsten Automatismen beim Übergang von distalen in proximale Reize Verständnislücken, die jedem Scheunentor Ehre machen, und von denen völlig unabsehbar ist, was sie jemals schließen sollte.
Mit ziemlicher Sicherheit wäre es falsch, die Anteile, die naturale Mitgift und Spontaneität beim Erkennen von Ähnlichkeiten haben, gegeneinander ausspielen zu wollen. Als John Searle einmal versuchte, Metaphern als Ähnlichkeitsverhältnisse zu verstehen, stellte er fest, dass Metaphern wie "Sally ist ein Eisblock" nicht analysiert werden konnten, indem man die Merkmale auflistet, die Sally und ein großer, kalter Würfel gemeinsam haben.
„Wenn wir die verschiedenen charakteristischen Eigenschaften von Eisblöcken buchstäblich aufzählen würden, würde keine von ihnen auf Sally zutreffen. Selbst wenn wir die verschiedenen Überzeugungen, die Menschen über Eisblöcke haben, einbringen würden, wären sie für Sally nicht buchstäblich wahr. (…) Emotional zu sein ist kein Merkmal von Eisblöcken, da Eisblöcke überhaupt nicht zu dieser Art von Angelegenheiten gehören. Wenn man darauf bestehen möchte, dass Eisblöcke buchstäblich nicht reagieren, müssen wir nur darauf hinweisen, dass dieses Merkmal immer noch nicht ausreicht die metaphorische Äußerungsbedeutung zu erklären, (…) denn in diesem Sinne reagieren Lagerfeuer auch nicht.“
Searle schließt daraus:
„Es gibt . . . ganze Klassen von Metaphern, die ohne zugrunde liegende Ähnlichkeitsprinzipien funktionieren. Es scheint eine Tatsache zu sein, die unsere geistigen Fähigkeiten betrifft, dass wir bestimmte Arten von Metaphern ohne die Anwendung irgendwelcher zugrunde liegenden "Regeln" oder "Prinzipien" interpretieren können, außer der bloßen Fähigkeit, bestimmte Assoziationen herzustellen. Ich kenne keinen besseren Weg, um diese Fähigkeiten zu beschreiben, als zu sagen, dass es sich um nicht repräsentative mentale Fähigkeiten handelt.“3
Das würde ich in der Tat etwas anders beschreiben. Searle hat völlig recht: Es geht um eine nicht repräsentative mentale Fähigkeit. Aber in seiner Einschätzung, dass das mit Ähnlichkeiten nichts zu tun hat, liegt er falsch. Über was er hier stolpert, sind meines Erachtens gerade die kreativen Akte, die Ähnlichkeiten überhaupt erst erzeugen und die die Voraussetzungen für Repräsentationen abgeben, wenn man sie später erinnert. Denn soviel ist klar: Nachdem die Metapher einmal in der Welt ist, sind sich Sally und der Eisklotz sehr wohl ähnlich. Warum? Ganz einfach: Sally ist ein Eisklotz!
Das Erkennen von Gesichtern zählt zweifellos zu den wichtigsten sozialen Wahrnehmungsleistungen des Menschen. Wir haben uns bereits sehr weit daran gewöhnt, nicht mehr danach zu fragen, worin der Unterschied bestehen könnte, ob ein Mensch einen anderen Menschen an seinem Gesicht erkennt oder ein Computersystem die Identität einer Person auf einem Überwachungsvideo. Es kommt uns vor, als sei das genau die gleiche Leistung, nur dass die Maschine weniger Fehler macht.
Ich bin weit davon entfernt, im Vergleich von menschlicher und künstlicher Intelligenz einzig und allein einen Fehler zu sehen, der sie dennoch ist und bleibt. Ganz im Gegenteil. Manche Fehler können sich als äußerst produktiv herausstellen. Hätte Antoine Henri Becquerel nicht 1896 unvorsichtigerweise seine Uranpräparate in die selbe Schublade wie seine Photoplatten gelegt, hätte er die Gelegenheit verpasst, radioaktive Strahlung zu entdecken.
Empirie und Induktionsproblem
Was ist beim Umgang mit Zufällen für alle empirischen Wissenschaften essentiell? Etwas empirisch bestimmen heißt, mit Zufällen zu rechnen, gerade das als unumstößlich anzunehmen, was einem Beobachter schlicht und einfach zufällt. Wenn es drei Ticks sind, die das Messgerät hören lässt, dann sind es genau drei und nicht vier. Das ist das Gebot der empirischen Wahrhaftigkeit. Ein anderes Messgerät hätte vielleicht vier vermeldet, und dann hätte man auch vier berichtet. Zur Wahrhaftigkeit gehört also auch die genaue Beschreibung des Versuchsaufbaus, damit Ergebnisse vergleichbar bleiben. Im Denken den Zufall aufzubewahren, ist also gar nicht so leicht. Die kleinste Willkür und selbst ein unbedachtes Verschweigen lassen den Zufall sofort verschwinden und fälschen das Experiment. Ziel jeder empirischen Wissenschaft, dieser mit Lauterkeit vollführten Übung, ist jedoch das glatte Gegenteil. Lässt sich welche Menge von Zufällen auch immer im Hinblick auf eine bestimmte Fragestellung verallgemeinernd mathematisch charakterisieren und wird solch eine Beschreibung als Regel für zukünftiges Verhalten verstanden, stellt das eine Reduktion des Zufälligen dar, die man sich drastischer nicht vorstellen kann. In diesem Sinne ist jedes empirische Wissen im Kern reduktionistisch. Das wird heute allgemein akzeptiert, auch wenn David Hume schon vor 300 Jahren darauf hingewiesen hat, dass sich aus der Beobachtung empirischer Ursache-Folge-Beziehungen nicht auf konstante Ursache-Wirkungsbeziehungen schließen lässt. Der Schluss von Einzelfällen auf allgemeine Gesetze bleibt unsicher und unterbestimmt. Das war das Induktionsproblem. Der Zufall, der systematisch ausgeblendet ist, ist der kleine Schritt vom gegenwärtigen Augenblick in den nächstfolgenden Moment. Man kann es auch so ausdrücken: Jede Reduktion von Kontingenz, jede Zusammenfassung von Zufällen in Gesetzen bleibt problematisch. Auch dann, wenn wir, woraus die auf Hume nachfolgende Diskussion um das Induktionsproblem bis heute hinausläuft, keine bessere Möglichkeit haben, als immer wieder neu darauf zu wetten, dass unsere Reduktionen, unsere Gesetzesbehauptungen stimmen und ihnen doch dabei genug zu misstrauen, um die Finger davon zu lassen, wenn sie empirisch falsch werden. Gleichzeitig zu reduzieren und dabei die Augen offen zu halten ist das Spannungsverhältnis jeder wissenschaftlichen Arbeit.
Wenn Hume im Traktat über die menschliche Natur unseren Glauben an induktive Beweise unseren Gewohnheiten zuschreibt, aus denen Erwartungen geworden sind, ist ein Schematismus des Wiedererkennens genau getroffen. In jedem Wissen steckt ein Moment der Erwartung. Wir erwarten, bestätigt zu finden, was wir zu wissen glauben. Damit grenzen wir Zufälle aus, die Zufälle des Neuen mit Blick nach vorne in der Induktion ebenso wie die Zufälle des Alten, all das, was uns an Daten nicht signifikant erscheint. Gesichtserkennung ist dafür geradezu das Musterbeispiel. Wir sind beim Erkennen von Gesichtern Meister in der Kunst, Zufälliges zu übersehen. Und wir machen daraus einen Grundpfeiler unseres sozialen Zusammenlebens.
Wenn ein Beweis der Induktion zu führen ist, müsste man ihn evolutionsgeschichtlich führen.
Um so interessanter ist der praktische Nachweis, den die KI führt, in wieweit eine solche geregelte Fokussierung, also eine ziemlich lange Geschichte erfolgreicher Erwartungen, im Grunde ein Zufallsgeschehen ohne all zu präzises Gedächtnis ist. Nicht nur das. Die KI liefert gleich auch ein Modell dafür, wie man sich das vorzustellen hat und geeignete Algorithmen, um die Modelle abzuarbeiten.
Henne oder Ei?
Wie können zwei Eier einander ähnlich sein? Sie haben vielleicht die selbe Farbe, die selbe Größe, die selbe Form. Aber sind das gute Antworten? Wohl eher nicht. Haben sie überhaupt die selbe Farbe? Ist nicht das eine braun und das andere weiß? Das eine größer als das andere? Und sind sie nicht ungleich rund, ungleich schwer? Und ist nicht vielleicht das eine doch eher eine Kugel? Und warum ist dem Gartenrotschwanz das Kuckucksei nicht aufgefallen? Ist es nicht bläulich wie sein eigenes, aber doch deutlich größer? Hat der Gartenrotschwanz seine Eier vielleicht gar nicht auf Ähnlichkeiten hin untersucht? Hätte er das vielleicht besser getan? Vielleicht wären ihm die Unterschiede aufgefallen. Sind sie nicht, und so muss er das Kuckucksei brüten. Wir reden im Gleichnis, schließlich geht’s um einen Vogel. Aber wir dürfen auch im Gleichnis reden, denn noch ist kein Unterschied gemacht.
Keinem Kind geht das so. Es unterscheidet bestimmte Gesichter und bestimmte Stimmen (aber keineswegs alle) schneller und sicherer als die chinesische Polizei. Und wo nicht, wo es Mutti zu einer Fremden sagt, wurde es erheblich traumatisiert.
Was macht Ähnliches ähnlich? Die klassische Antwort lautet etwa:
„Ähnlichkeit, traditionell die Übereinstimmung zweier Dinge, Systeme oder Ereignisse in einigen (aber nicht notwendigerweise allen) Merkmalen. Neuerdings hat man Ähnlichkeit auch dadurch zu charakterisieren versucht, daß sich ein Ding (bzw. System, Ereignis) in ein zu ihm ähnliches durch eine Transformation überführen lasse, die bestimmte für wesentlich erachtete Eigenschaften oder Größen unverändert läßt; die Ähnlichkeit erscheint dann als Spezialfall der Analogie. In der Geometrie erhält man einen Ähnlichkeitsbegriff durch Verallgemeinerung des elementargeometrischen Begriffs der Ähnlichkeit zweier (ebener) Dreiecke, die als ihre Übereinstimmung in entsprechenden Winkeln definiert ist.“4
Ähnlichkeit also von Analogie als Verhältnisgleichheit oder partieller Gleichheit von Eigenschaften oder von Transformierbarkeit mit Verweis auf den Unterschied zwischen strukturellen und funktionalen Analogien.
Aber fehlt da nicht etwas? Wird da nicht etwas Fundamentales still vorausgesetzt? Muss man nicht Ähnlichkeiten zu allererst einmal erkennen, bevor man sie nutzen kann? Ist diese gelbe Fläche wirklich gelb oder nicht schon orange? Heute arbeiten wir mit Definitionen für Gelb. Gelb ist z.B. in der RGB-Skale eindeutig durch die Werte 255,255,0 bestimmt. Ähnlichkeit ist dann allerdings kaum noch „Übereinstimmung zweier Dinge... in einigen ... Merkmalen“. Das wäre Gleichheit. Ähnlichkeit wäre viel eher geringfügige Abweichung in mindestens einem Merkmal. Und woher kommt das Maß? Aber auch ohne solche definierenden Quantitäten: ein Apfel ist größer als eine Erdbeere. Eine Melone ist ebenfalls größer als eine Erdbeere. Weil also Apfel und Melone diese Eigenschaft, größer als eine Erdbeere zu sein, gemeinsam haben, sollen sie sich deshalb untereinander ähnlicher sein als der Erdbeere? Offenbar hängt die Feststellung von Ähnlichkeit von der Frage ab, die man stellt. Das wäre der funktionale Aspekt, von der Hinsicht, nach der man fragt. Erdbeere, Apfel und Melone sind allesamt essbar und wohlschmeckend. Wenn es Zusammenhänge gibt, in denen eine Vielzahl von Hinsichten relevant sind, die für die Entscheidung auf die Frage nach der Ähnlichkeit in Frage kommen, muss man dann nicht die jeweiligen Antworten gewichten? Ist nicht die Gewichtung ein zentrales Element des Erkennens. Neurowissenschaften und KI-Forscher sind sich darin einig. Für sie ist das Gewichten, die Bestimmung der Relevanz zentral für jedes Erkennen.
Der Vergleich, das nicht, das nicht, das ja, das wieder nicht … Etwas folgt auf etwas, wird verglichen, unterscheidet sich, ist gleich. Nicht völlig identisch, sondern (eins meiner Lieblingsworte:) 'good enough'. A ist B ähnlicher als C. Aus einer bestimmten Entfernung, also in den Grenzen einer bestimmten Dimension und Genauigkeit, ist A von B nicht zu unterscheiden. Wir haben also zwei Arten von Unterschieden, einen Unterschied von A zu B oder zu C, der mehr oder weniger groß sein kann. Wir haben z.B. Pixel auf einem digitalen Foto, Pixel aus abgestuften Grauwerten von 0 für schwarz bis 1 für weiß. Im Grunde können gerade die sich niemals ähnlich sein, denn sie haben alle entweder voneinander unterschiedliche Grauwerte oder genau identische, können also entweder nur verschieden oder gleich, aber nie ähnlich sein. Es muss also eine zweite Art von Unterschied geben, einen Unterschied, der nicht mehr quantifiziert ist, sondern dessen Quantitätsunterschied schwindet, undeutlich wird, verwischt, gegen Null geht, ohne dass es dabei zu Identität kommt, denn auch das würde Ähnlichkeit auflösen. Der Unterschied wäre verschwunden, der das Ähnliche davon abhält, in eins zu fallen. Nun handelt es sich allerdings streng genommen nicht um zwei Arten des Unterschieds, sondern um ein Undeutlich-Werden des Unterschieds bei zunehmendem Abstand, um ein Phänomen schärferer und unschärferer Fokussierung, bei der der Unterschied von etwas zu ihm Ähnlichen früher unscharf wird als der Unterschied von etwas zu ihm Unähnlichen. A sei also B ähnlicher als C oder D. Aus einer bestimmten Entfernung schwindet der Unterschied von A und B, noch nicht jedoch der von A und C oder A und D. Man kann es jetzt mit der Fehleinstellung des Fokus weiter treiben. Irgendwann verschwindet auch der Unterschied zwischen A und C und A und D, dabei der von A zu C früher oder später als der von A zu D, was heißen würde, dass wiederum eins von beiden, C oder D A ähnlicher ist. Um das nachzuvollziehen, muss man kein Mathematiker sein oder sonst irgendeine Spezies von Theoretiker, man muss einfach nur seinen Blick fokussieren können, wie es praktisch jeder kann, der nicht blind ist.
Das allein reicht allerdings immer noch nicht aus, um Ähnlichkeiten festzustellen. Es muss noch dazukommen, dass nachdem das Verschwimmen des Unterschieds von A und B festgestellt ist, ein neuer Unterschied gemacht wird, nämlich der von B zu C und D. Während nämlich B sich bei zunehmender Fokusunschärfe, in der Bewegung der Auflösung des Unterschieds als A ähnlich erweist, ist festzuhalten, dass C und D dem Objekt A gerade nicht ähnlich sind. Denn nur weil ein Unterschied sich auflöst ist ja noch nicht gesagt, dass das irgendetwas zu bedeuten hat, dass sich daraus am Ende sogar irgendein Erkenntnisakt ableiten ließe. Vielmehr muss Differenz grundsätzlich erhalten bleiben und zwar als die Differenz von C und D zu A. Und diese Unähnlichkeit des A von C und D, die sich untereinander insofern gleich sind, als sie beide A unähnlich sind und damit ungleich von B, ist die Voraussetzung, dass A und B nicht ineinander fallen, dass sich also Ähnlichkeit sowohl von Identität als auch von Differenz unterscheidet.
Der logische Trick bei solcher Genealogie der Ähnlichkeit, so wie wir sie eben erzählt haben ist, dass wir von der Ähnlichkeit als von einer verschwindenden Differenz erzählten. Mit dem wahrscheinlich gleichen Recht könnten wir von einer Identität erzählen, von der sich etwas, nämlich das Ähnliche ablöst, um sodann in größerer Nähe als das Unähnliche durch einen Akt des Erkennens festgehalten zu werden. Wir bevorzugen keine von beiden Erzählungen. Wir sehen zunächst wenigstens keinen Grund, warum die Denkbewegung nicht frei in der Wahl der Richtung sein sollte.
Womit wir der Frage nicht ausweichen können, was hier Henne ist und was Ei. Ist die Identität das erste und also die Voraussetzung oder die Differenz oder ist am Ende die Ähnlichkeit die Voraussetzung sowohl des Unterschieds wie der Identität? Wie hat man sich die Verhältnisse vorzustellen?5 Kann es darauf überhaupt eine eindeutige Antwort geben oder ist das ganze, die Bewegung des Erkennens, moderner, aber reduktionistischer gesagt, die Mustererkennung, ein einziger großer Zufall?
Algorithm first!
Die Antwort, die man darauf geben kann, hängt von den Mitteln ab, die man hat, wenn man die Frage stellt. Das lernen wir in den letzten Jahrzehnten, in denen sich die Digitaltechniken so rasant entwickelt haben. Sie fällt völlig anders aus je nach den Mitteln, die zur Verfügung stehen, um sie zu beantworten. Grob gesagt hatte bei aller Reklamation des Unterschieds bis ins 20. Jahrhundert hinein die Identität die Oberhand in der Rolle einer Henne, die die Ähnlichkeit ausbrütet. Das ändert sich im 20. Jahrhundert mit der Turingmaschine und ganz allgemein durch die Rolle von Algorithmen. Statt was ist Henne und was Ei fragt man jetzt: wie geht das Brüten? Die Frage ist dann nicht mehr allein die nach dem Verhältnis von Identität und Differenz bei der Feststellung von Ähnlichkeiten, sondern die nach einem geeigneten Programm. Wichtiger als Identität und Differenz wird darin ein Papierstreifen und eine Gerätschaft, die ihn vor- und zurückschiebt und darauf nach einer einfachen Regel Markierungen anbringt, denn genau das, wenn auch als Gedankending, ist eine Turingmaschine ja bekanntlich. Und was dabei zentral ist: Sie soll auf diese Weise nicht nur Rechenaufgaben lösen, sondern Aufgaben aller Art. Es handelt sich um eine Universalmaschine, die die unterschiedlichsten Aufgaben löst, die sich dem Menschen stellen, die – metaphorisch gesprochen – am Ende sogar Hennen produziert, die Eier legen. Wir sind bis heute begeistert, als wie universal sie sich herausgestellt hat.
Was sie nicht kann ist, eine Vorstellung vom Zeit- und Energiebedarf ihrer eigenen Prozesse zu vermitteln. Die Turingmaschine ist ein Modell. Und wir sollten zumindest andeutungsweise sagen, was ein Modell ist. Eine Landkarte ist ein Modell für ein Land. Man meint allgemein, es sei deshalb ein Modell für ein Land, weil sie dem Land ähnlich sei, nur eben in einem viel kleineren Maßstab. Will man dieses Land aber als Wanderer durchwandern, merkt man, wie unähnlich das Modell dem Land ist, bildet es doch die Anstrengungen nicht ab, die es macht, das reale Land bei Wind und Wetter zu durchqueren. Eine gute Wanderkarte hilft da weiter. Google Map versucht sogar alles, um ganz unterschiedlichen Verwendern zu helfen, Autofahrern, Nutzern öffentlicher Verkehrsmittel, Fußgängern, also Leuten, die ziemlich unterschiedliche Anforderungen an Modelle haben. Modelle sind also immer nur, wir sagten das bereits, Modelle für bestimmte Fragestellungen. Kein Modell ohne Fragestellung und umgekehrt. Will man ein Modell verstehen, muss man herausbekommen, bei welcher Frage es überhaupt Orientierung bietet, um dann auch besser abschätzen zu können, wobei es nicht hilfreich ist. Eine Turingmaschine ist ein Modell, das bei der Frage Orientierung bietet: was kann man tun, um mit einer geordneten Abfolge einzelner Schritte Ziele zu erreichen? Zwei Einschränkungen: Vorausgesetzt, dass das Ziel überhaupt mit einer Folge von Einzelschritten erreichbar ist, was sich mit einer Turingmaschine nicht immer beweisen lässt. Zweitens ist die Turingmaschine kein ökonomisches Modell, das abschätzbar macht, wie viel Aufwand jeder einzelne Schritt und damit am Ende natürlich auch der Gesamtprozess kostet.
Man kann also schon von daher nicht sagen, dass sich mit Computern, die nach wie vor wie Turingmaschinen funktionieren, alle Ziele erreichen lassen, die Menschen sich so stellen. Aber das können Menschen, was ihre eigene Leistung angeht auch nicht. Womit wiederum nicht gesagt ist, dass das, woran Maschinen scheitern, irgend etwas damit zu tun hat, woran Menschen scheitern.
Es zeigt sich, dass man allein mit der Idee der Turingmaschine, mit der Verschiebung des Fokus von der Gleichung zum Algorithmus, oder mit dem Gedanken, dass eine virtuose technische Beherrschung der Differenz von 1 und 0 der Schlüssel zur Beherrschung einer jeglichen Aufgabe sein könnte, die sich dem Menschen stellt, noch lange keine angemessene Vorstellung vom Zeit- und vom Energiebedarf hinbekommt, den die Entwicklung komplexer semantischer Strukturen stellt und der Bewältigung komplexer Aufgaben, die darüber möglich wird.
Es stellt sich also zunehmend die Frage nach der materiellen Grundlage, denn das reine Konzept der Turingmaschine gibt nicht die leiseste Idee vom zeitlichen und energetischen Ablauf von Prozessen, die in der Lage sind, einen Zustand zu erreichen, in dem es überhaupt Sinn macht, Ähnlichkeiten festzustellen. Das wäre ein Zustand, den der Gartenrotschwanz, was das Kuckucksei angeht, bisher nicht erreicht hat.
Diese Unfähigkeit, von einem an Turingmaschinen orientierten Denken auf die Frage nach Zeitlichkeit und materiellen Voraussetzungen von Ähnlichkeiten zu antworten, dürfte einer der Gründe gewesen sein, warum die Entwicklung neuronaler Netze in den 80er Jahren ins Stocken geraten war. Die technische und ökonomische Entwicklung bei Hard- und Software seither ist aber auch der Hauptgrund, warum sie heute wieder läuft.
Hinterm Horizont der Miniaturisierung
Die Chancen zur Miniaturisierung scheinen an ein vorläufiges Ende gekommen zu sein.
Bisher galt moore’s law, das seit 1965 besagt, dass sich die Komplexität integrierter Schaltkreise mit minimalen Komponentenkosten regelmäßig verdoppelt; je nach Quelle werden 12, 18 oder 24 Monate als Zeitraum genannt. Leider scheint diese Entwicklung gerade zum Stillstand zu kommen, weil ab einer gewissen Miniaturisierung relativistische Tunneleffekte ins Spiel kommen und weil die Lithographie an ihre Grenzen gerät, die bei der Chipherstellung verwendet wird.
„Obwohl das Moore'sche Gesetz jahrzehntelang galt, verlangsamte es sich irgendwann um das Jahr 2000 und zeigte bis 2018 eine etwa 15-fache Lücke zwischen Moores Vorhersage und der aktuellen Fähigkeit, eine Beobachtung, die Moore 2003 machte und die unvermeidlich war. Es wird erwartet, dass die Lücke weiter wächst, wenn die CMOS-Technologie an grundlegende Grenzen stößt.
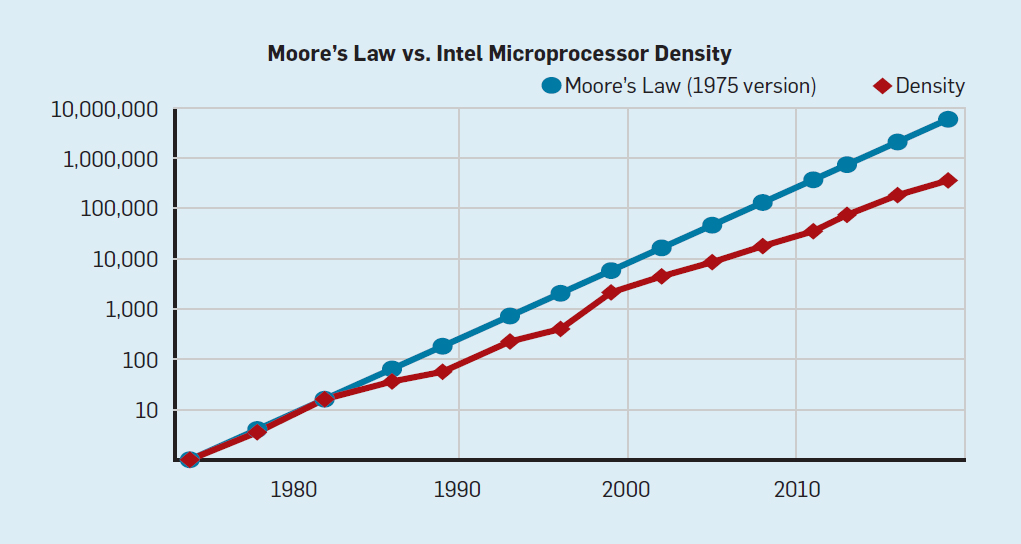
Begleitend zum Moore'schen Gesetz wurde von Robert Dennard eine Projektion namens "Dennard-Skalierung" erstellt, die besagt, dass mit zunehmender Transistordichte der Stromverbrauch pro Transistor sinken würde, sodass die Leistung pro mm2 Silizium nahezu konstant wäre. Da die Rechenleistung von mm2 Silizium mit jeder neuen Technologiegeneration zunahm, wurden Computer energieeffizienter. Die Dennard-Skalierung begann sich 2007 erheblich zu verlangsamen und verblasste bis 2012 fast vollständig.
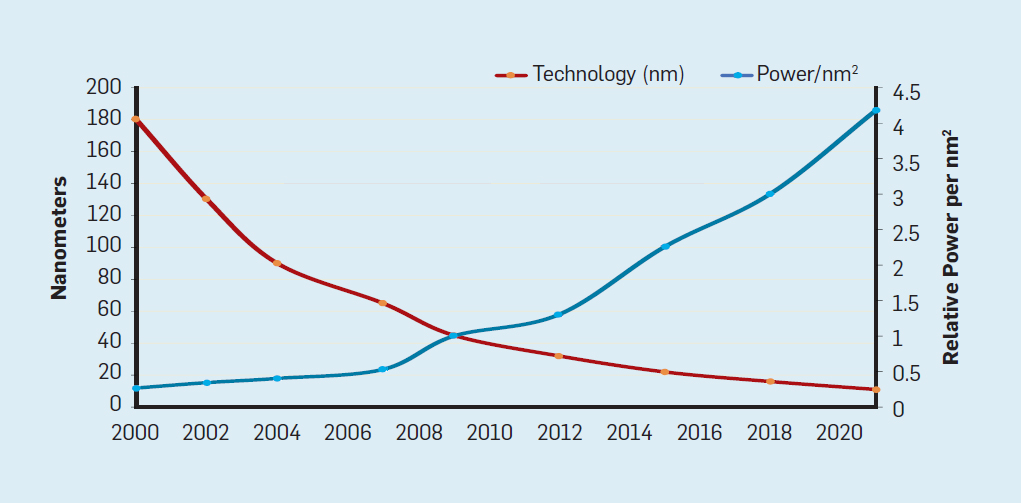
Zwischen 1986 und etwa 2002 war die Nutzung der Parallelität auf Befehlsebene die wichtigste Architekturmethode zur Leistungssteigerung und führte zusammen mit der Verbesserung der Geschwindigkeit von Transistoren zu einer jährlichen Leistungssteigerung von ca. 50%. Das Ende der Dennard-Skalierung bedeutete, dass Architekten effizientere Wege finden mussten, um Parallelität zu nutzen.“6
Derzeit werden daher parallel zahlreiche Lösungsansätze zur Ablösung der klassischen Halbleitertechnik erprobt. Kandidaten für grundsätzlich neue Technologien sind die Erforschung von Nanomaterialien wie Graphen, dreidimensionale integrierte Schaltkreise, also die Erhöhung der Transistorzahl pro Volumen und nicht mehr nur pro Fläche, Spintronik und andere Formen mehrwertiger Logik, sowie Tieftemperatur- und Supraleiter-Computer, optische und Quantencomputer. Bei all diesen Technologien würde die Rechenleistung oder Speicherdichte gesteigert, ohne im herkömmlichen Sinn die Dichte an Transistoren zu steigern.
Was ebenfalls intensiv bearbeitet wird, und darauf heben John L. Hennessy und David A. Patterson in ihrem ausgezeichneten Übersichtsartikel „A New Golden Age for Computer Architecture“7 ab, sind innovative Hardwarearchitekturen, verbesserte Interpreter- und Compilertechnik und besserer Softwarebibliotheken.
Hennessy und Patterson geben dafür ein anschauliches Beispiel und führen aus, dass z.B. das einfache Umschreiben des Codes eines in Python geschriebenen Programms, einer Hochsprache, die im Informatikstudium gängig ist, in C die Leistung um das 47-fache steigert. Die Verwendung von parallelen Schleifen, die auf vielen Kernen ausgeführt werden, ergibt einen Faktor von ungefähr 7. Die Optimierung des Speicherlayouts zur Ausnutzung von Caches ergibt einen Faktor von 20, und ein letzter Faktor von 9 ergibt sich aus der Verwendung der Hardwareerweiterungen für die Ausführung von SIMD-Parallelitätsoperationen (Single Instruction Multiple Data) die in der Lage sind, 16 32-Bit-Operationen pro Befehl auszuführen. Insgesamt läuft die endgültige, hochoptimierte Version auf einem Multicore-Intel-Prozessor mehr als 62.000-mal schneller als die ursprüngliche Python-Version.
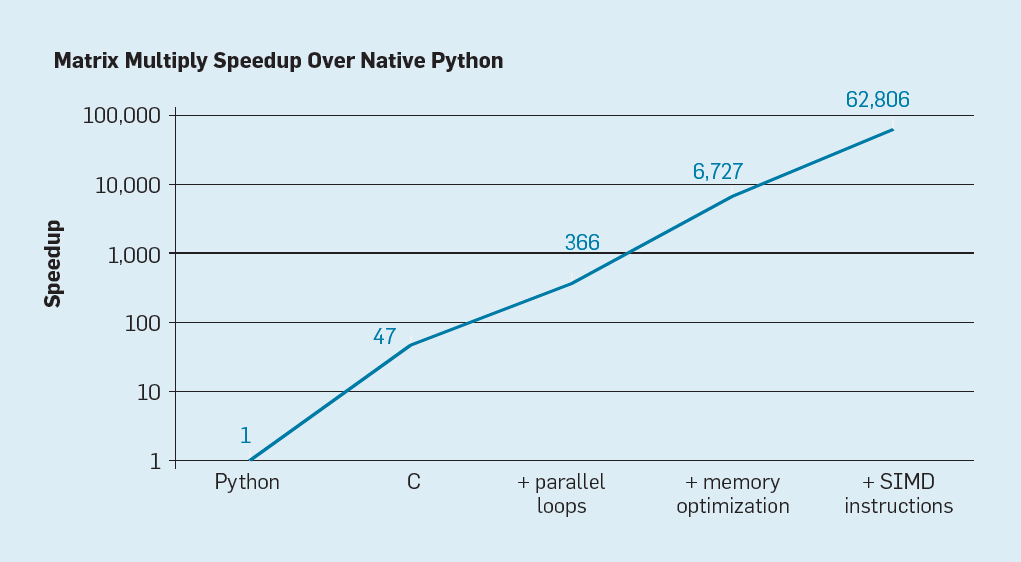
Mögliche Beschleunigung der Matrixmultiplikation in Python für vier Optimierungen.
„Eine interessante Forschungsrichtung betrifft die Frage, ob ein Teil der Leistungslücke mit neuer Compilertechnologie geschlossen werden kann, möglicherweise unterstützt durch architektonische Verbesserungen. Obwohl die Herausforderungen bei der effizienten Übersetzung und Implementierung von Skriptsprachen auf hoher Ebene wie Python schwierig sind, ist der potenzielle Gewinn enorm. Wenn sogar 25% des potenziellen Gewinns erreicht werden, können Python-Programme zehn- bis hundertmal schneller ausgeführt werden. Dieses einfache Beispiel zeigt, wie groß die Kluft zwischen modernen Sprachen, die die Produktivität von Programmierern betonen, und traditionellen Ansätzen ist, bei denen die Leistung im Vordergrund steht.“8
Wir werden uns gleich einen Eindruck davon verschaffen können, dass KI-Projekte Unternehmen sind, die dazu neigen, schneller Verwendung für neue Ressourcen zu entwickeln, als diese sich überhaupt bereitstellen lassen. Damit wird es praktisch unmöglich, ökonomische Restriktionen zu weiterhin zu ignorieren.
Weisen wir hier bereits darauf hin, dass die heutigen Silizium-basierten Recheneinheiten gemessen an der Frage, zu wie vielen Operationen pro Watt sie fähig sind Kohlenstoff-basierten wie dem Gehirn bei weitem unterlegen sind. Die informationsverarbeitende Leistung des menschlichen Gehirns ist um so beeindruckender, als seine Verarbeitungsgeschwindigkeit auf der Ebene der einzelnen Elemente ziemlich langsam ist. Sie liegt geschätzt bei ungefähr 100 Verarbeitungsschritten pro Sekunde9 gegenüber Millionen auf Seiten von Computern.
Post-Behaviorismus
Die Fähigkeit, Erkenntnis mit dem Erkennen von Ähnlichkeiten beginnen zu können, setzt entwicklungsgeschichtlich die Freiheit von den Direktiven ziemlich brachialer Stimuli voraus. Wenn ein Insekt wie etwa ein Seidenspinner durch ein Pheromon angelockt wird, hat das nichts mit der Wahrnehmung von Ähnlichkeiten oder mit irgendeinem Erkenntnisakt zu tun, sondern ist die angeborene Verhaltensantwort auf einen bestimmten biochemischen Nervenreiz.
Solches chemisch erzwungene Sozialverhalten kommt allerdings bei Säugetieren nicht vor. Das heißt allerdings nicht, dass es bei Säugetieren keine biochemische Rezeptivität gibt. Auch bei Säugetieren gibt es biologische Sekrete, die das soziale und sexuelle Verhalten beeinflussen. Deren Wirkungen unterscheiden sich nicht grundlegend von ähnlichen Einflüssen anderer sensorischer Systeme. Ihr Einfluss auf das Verhalten hängt von Lernen und Kontext ab und kann nicht von kognitiven Prozessen höherer Ordnung getrennt werden.10
Eine ganz andere Frage, die sich hier anschließt, ist allerdings, ob man sich das Erkennen von Ähnlichkeiten gänzlich ohne Sinneswahrnehmungen vorstellen kann. Wenn uns Sinneswahrnehmungen kein bestimmtes Verhalten diktieren wie das Pheromon dem Falter, wie kann es dann überhaupt zu bestimmtem Verhalten kommen und wozu braucht die Verhaltensbestimmung dann überhaupt noch Sinneswahrnehmungen? Selbst wenn Sinneswahrnehmungen kein bestimmtes Verhalten determinieren, ziehen veränderte Sinneswahrnehmungen ja in der Regel auch ein verändertes Verhalten nach sich. Ansonsten wäre Verhalten auf Sinneswahrnehmungen nicht bezogen, liefen wir gleichsam mit geschlossenen Augen durch die Welt. Wie kommt es überhaupt elementar zu Semantik?
Bemerkenswert dabei ist ein Spannungsverhältnis, dass Turingmaschinen in Form neuronaler Netze ein Ort, wenn nicht sogar bisher der einzige Ort sind, an dem man semantischen Netzen bei ihrer Entstehung überhaupt zusehen kann. Was nicht heißen muss, dass semantische Netze in der menschlichen Kommunikation auf eine vergleichbare Weise entstehen. Hier bei neuronalen Netzen greift man ein, indem man Aufgaben stellt, die aus einem unabschätzbar höher komplexen Netz kommen, nämlich dem der menschlichen Semantik.
Man versteht am MIT und bei Google Intelligenz ganz allgemein als die Fähigkeiten, wie auch immer Informationen zu generieren, die für anstehende Entscheidungen benötigt werden. Wo immer Computeralgorithmen diese Fähigkeit zeigen, spricht man von Artificial Intelligence. Machine learning wäre die Teilmenge der KI, bei der Maschinen nicht eigens für die Lösung konkreter Fragestellungen programmiert werden müssen, sondern geeignete Lösungswege selbständig finden. Deep Learning ist noch einmal die Untermenge des Machine learning, bei der zur Lösung neuronale Netze eingesetzt werden.11
Bei der KI-Software ist der Fortschritt derzeit extrem schnell; pro Tag werden in diesem Bereich allein auf Arxiv.com mehr als hundert Aufsätze mit neuen Forschungsresultaten publiziert, die wir hier unmöglich auch nur ansatzweise überblicken können.
Machine-learning-Algorithmen sind letztlich Itterationsautomaten, die typischerweise darauf abstellen, innerhalb der untersuchten Daten selbst Regeln zu finden, anhand deren sinnvolle Information von sinnloser unterscheidbar ist, wobei es natürlich immer von der gestellten Frage abhängt, was sinnvoll ist und was nicht. Beim traditionellen machine learnig müssen etwaige Regeln, die in den Rohdaten stecken könnten, von Ingenieuren bestimmt und passende Algorithmen programmiert werden. Daher sind die klassischen Lösungen nur schwer skalierbar. Genau diese Hürde soll beim deep learning überwunden werden.
Anmerkungen:
1 Was das Sehvermögen angeht, vgl zur Einführung
2 Der Begriff 'angeboren' besagt heute oft nicht viel. Er bezieht sich auf Merkmale, Eigenschaften oder Fähigkeiten und sagt einfach nur, dass etwas nicht erst durch Lernen erworben worden ist, sondern dass es bestimmte Lebewesen irgendwie von Anfang an auszeichnete. Gerade weil der Begriff 'angeboren' armselig und unbestimmt ist, bietet er von jeher Raum für Rassismus. Erklärt ist damit nichts. Etwas sei angeboren hören wir meist nur dann, wenn Unterschiede gemacht werden sollen, die zu machen man nicht weiter rechtfertigen will, oder wenn 'etwas eben so ist, wie es ist'. Man hat ein Rätsel vor sich und beschließt, es dabei zu belassen. Diese Mauer zu durchbrechen war Darwins Verdienst.
3 John R. Searle, lntentionality: An Essay in the Philosophy of Mind (Cambridge, England: Cambridge University Press, 1983)
4 Mittelstraß, Enzyklopädie Philosophie und Wissenschaftstheorie, Bd.1
5 Wir wollen an dieser Stelle nicht auf die Antwort zurückkommen, die Jacques Derrida darauf gibt. Das haben wir anderenorts schon gemacht.
7 Ebd.
8 Ebd.
9 Feldman, J. A. (1985). Connectionist models and their applications: Introduction, Cognitive Science 9: 1–2.
10 Doty, R. L. (2010). The Great Pheromone Myth. Baltimore: Johns Hopkins University Press.
11 So Alexander Amini in: MIT Introduction to Deep Learning 6.S191: Lecture 1 *New 2020 Edition* Foundations of Deep Learning
zurück ...
weiter ...
Ihr Kommentar
Falls Sie Stellung nehmen, etwas ergänzen oder korrigieren möchten, können sie das hier gerne tun. Wir freuen uns über Ihre Nachricht.